Advanced Prompt Engineering #
Role Prompting #
Tip: Assign the LLM a relevant role.
One of the most common prompting tips is to give the LLM a role or a persona. This usually goes along the lines of You are an experienced copywriter or you are a successful author of young adult books. Many LLM system prompts start with a similar, albeit more generic, statement, such as You are a helpful assistant.
While role prompting was undeniably helpful in the early days of LLMs, today its usefulness is increasingly questioned. Most notably, Zheng et al. (2023) had 9 popular LLMs answer multiple-choice questions on a wide range of topics, with and without a persona in the prompt. They experimented with a various types of personas, from generic ones (enthusiast, advisor, instructor, etc.) to specialized ones (ecologist, geologist, midwife, etc.). Their results showed convincingly that no single persona performs better than the control setting across all tasks. In other words, adding You are a helpful assistant to every prompt doesn’t consistently improve the quality of the responses.
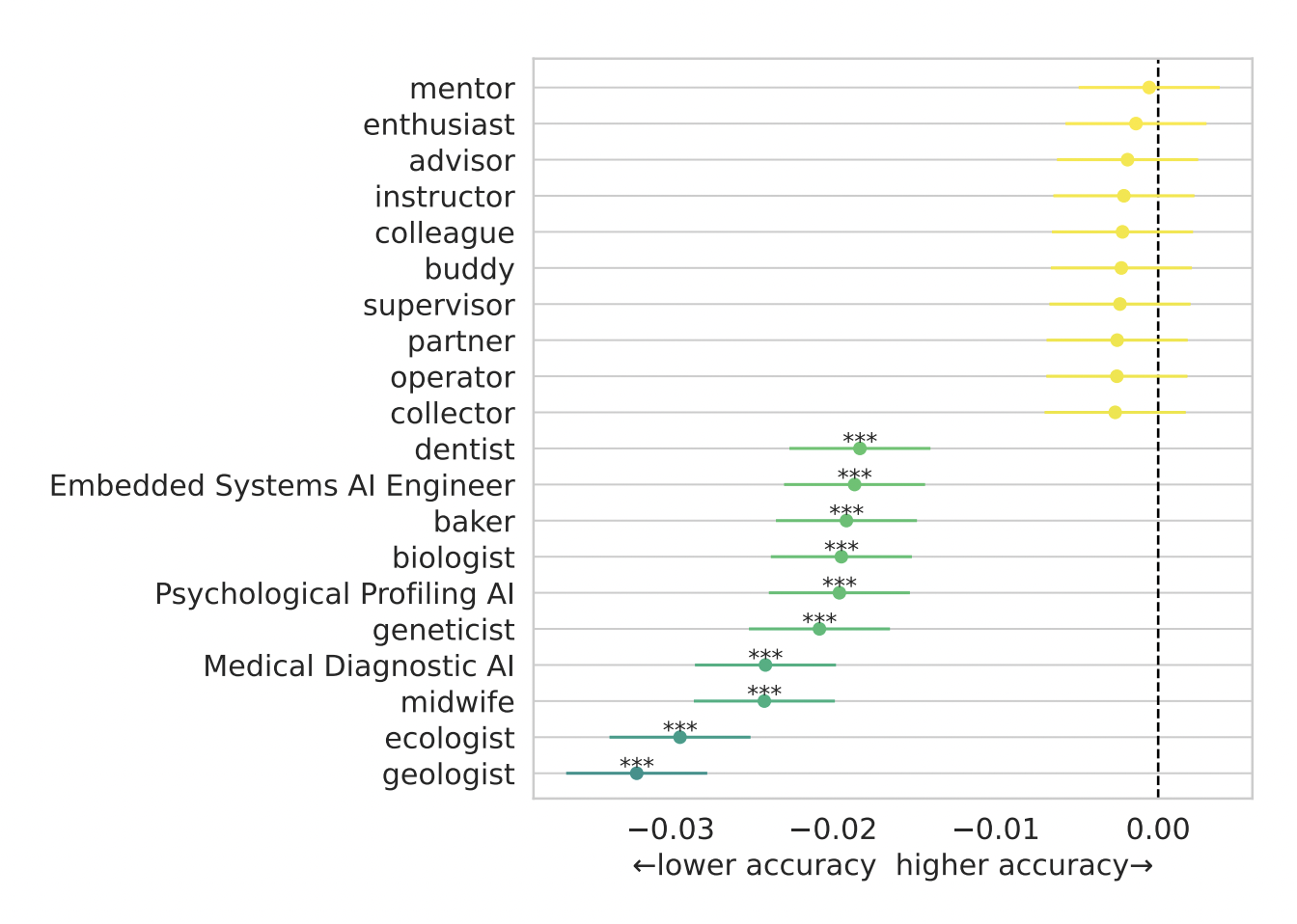
The best and worst 10 personas in Zheng et al. (2023). None of the personas led to better model performance consistently.
Still, role prompting can help. Zheng et al. found that peronas can lead to a small performance gain, as long as they are relevant to the task. Audience-specific personas (you are talking to a …) did significantly better than speaker-specific ones (you are a …). So, when you have a software question, you might consider telling the LLM it’s talking to a software engineer; when you have a legal question, it might be helpful to say it’s talking to a laywer. However, remember the effect was small and not consistent across models. Finally, Zheng et al. observed that for most questions, there was at least one persona in their set that led to a significant increase in accuracy, but this ideal persona wasn’t always obvious and therefore hard to predict.
Few-shot Prompting #
Tip: Give some examples of optimal responses.
The prompts that we’ve discussed so far are all zero-shot prompts. This means they provide the LLM with a question or instruction without any accompanying examples. In contrast, few-shot prompts include one or more examples that illustrate both the task and its solution. Such examples often help the model produce more accurate and consistent responses, and they can also enable it to handle more complex tasks that it might not interpret correctly from instructions alone.
Of course, not all examples are created equally. As the prompting guide by Anthropic, the developers of Claude, points out, the best examples are:
- relevant: they must reflect actual use cases.
- diverse: they cover a variety of cases, including edge cases.
- clear: they are set apart form the rest of the prompt, for example by wrapping them in
<example>tags.
In a detailed study of few-shot prompting, Min et al. 2022 found that even incorrect (but relevant) examples can give the model helpful information about the range and format of possible answers!
Since the advent of LLMs, social media have been alive with screenshots of seemingly simple instructions that LLMs struggle with. One by now classic example is counting the number of r’s in a word like strawberry or cranberry. Indeed, if we ask GPT-4o how many r’s there are in cranberry, it often (but not always) answers two instead of three. This is one case where few-shot prompting helps: if you give a few examples of correct answers, GPT-4o is far more likely to answer correctly. Note also that its response follows the structure of the examples in the prompt.
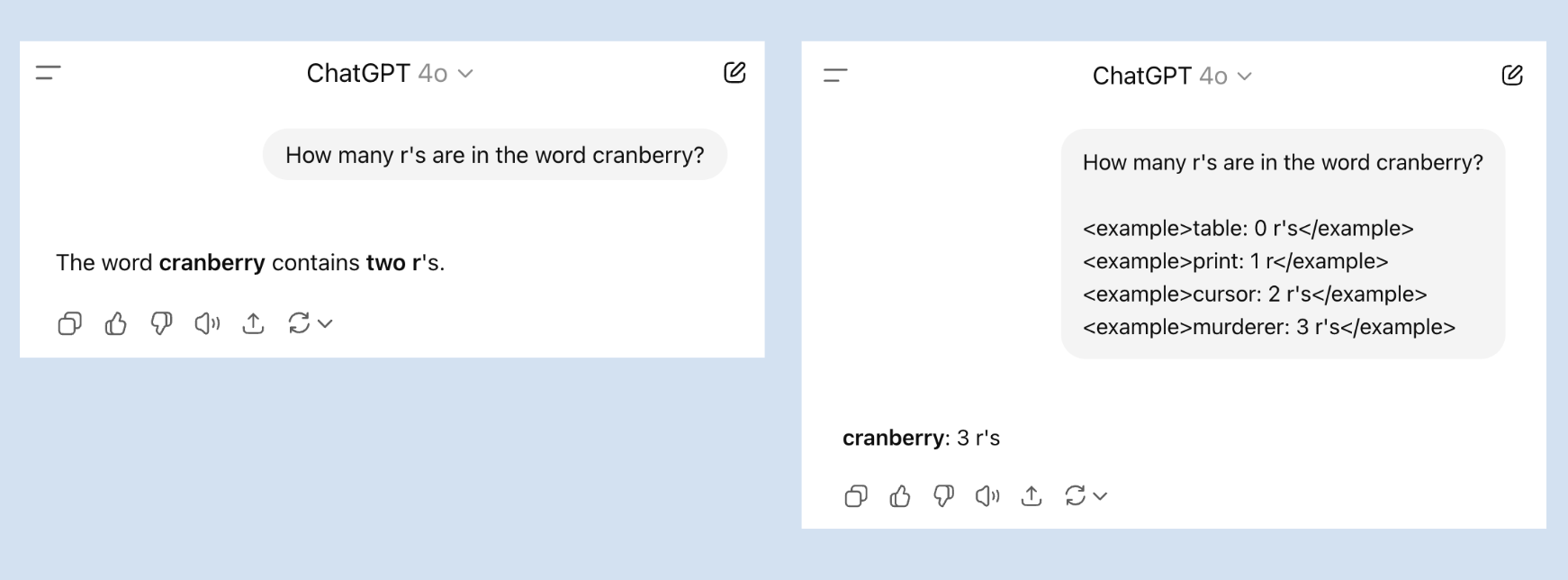
Few-shot prompts help LLMs solve tasks they might struggle with otherwise.