Prompting LLMs #
Prompt engineering #
The instruction we give to a language model is most commonly called a prompt. Crafting these prompts to elicit the best possible results is known as prompt engineering. Prompt engineering is a controversial skill. Some people thinks it is essential nowadays, while others believe it is becoming obselete as language models cotinue to improve. Personally I find the term prompt engineering a bit overstated. Getting good results from an LLM isn’t rocket science — it’s barely even a science at all. Still, there are some tricks of the trade that are useful to know.
Emotions and bribes #
Because LLMs are black boxes, prompt engineering can sometimes feel like black magic. For example, it has been shown that LLMs perform better at mathematics when they are told they play a role in Star Trek. ChatGPT is sensitive to emotional manipulation: it gives better results when you stress the quality is important — that when the response is unhelpful, you’ll be fired or an innocent kitten will die. Its responses also improve when you offer it money in return — the more money, the better. Google researchers found that their LLM doesn’t only work better when it works through complex tasks step by step, but also when it is told to “take a deep breath” first.
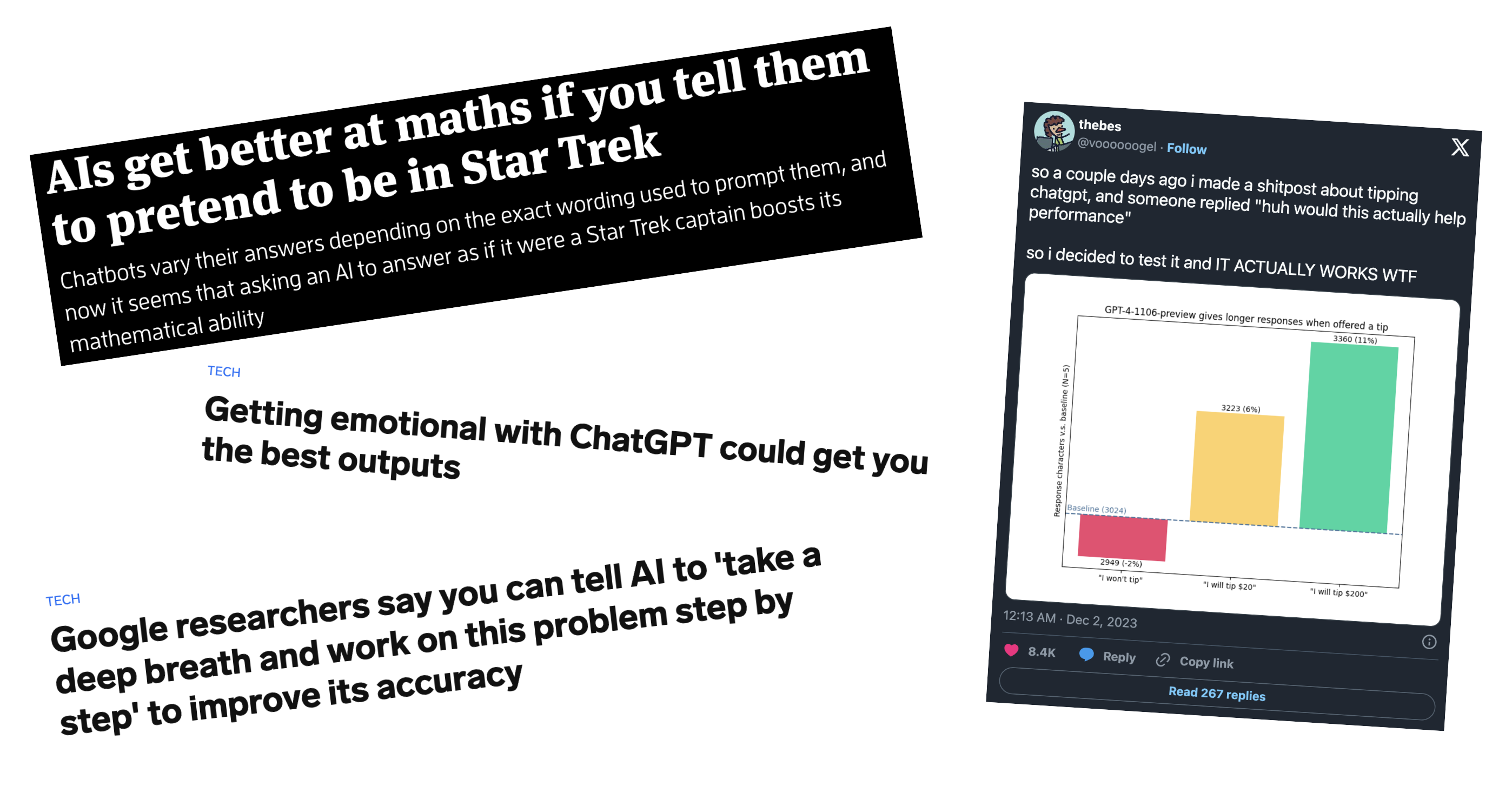
Funny as such findings may be, they can be very frustrating. Yes, they reveal that LLMs often behave like people — they have been trained on content that was created by people, after all. But who guarantees that this idiosyncratic behavior will occur in all models and all their available versions? Surely, there must be more robust prompting strategies?
AI as a new coworker #
The best rule of thumb for optimal prompting comes from American professor Ethan Mollick, who has an informative Substack about AI:
Treat AI like an infinitely patient new coworker who forgets everything you tell them each new conversation, one that comes highly recommended but whose actual abilities are not that clear.
Let’s break this down. First, it’s important to remember that no matter how capable a language model is, its weaknesses may surprise us. This is what we call the jagged frontier of AI: some tasks that humans find hard are simple for an LLM, and vice versa. For that reason, it’s important to experiment, so that you get a feeling for what a particular model can and cannot do well. Second, it’s helpful to see an LLM as a new coworker: they may be smart, but they don’t know much about their new job yet. Unless you give them very specific instructions, they may come back with a result that is very different from what you had in mind. Finally, the language model starts from a blank slate with every new conversation — unless, as we’ve seen before, it has a memory feature like ChatGPT.
Basic prompting rules #
In this section, we’re going to take a closer look at what it means to give an LLM specific instructions. What kind of information is useful to include in a prompt?
Rule 1: Be clear and direct #
Unclear prompt
Summarize this document
Clear prompt
I am writing an introductory book on AI. Summarize this scientific in one paragraph for a lay audience. Include:
- the title and authors of the paper
- its motivation
- its main innovation
- the most important experimental results
Like your smart new coworker, a large language model knows nothing about the context of a task. It does not know why you give it an instruction, what goal you want to reach and how you’d like to reach it. Therefore it generally pays off to give it this type of information. If you’re writing a text, for example, describe the target audience you have in mind and the style the LLM should use. If you’re performing another task, specify any context that is relevant, such as the organization you’re working for or what the results of this task will be used for. This will not only lead to more useful responses, but also ensure that the response you see will be more unique.
Rule 2: Work in steps #
Unclear prompt
Summarize this document in Spanish.
Clear prompt
Summarize this document. Then translate the summary to Spanish.
A second important rule is to break down complex task into simpler ones. For example, instead of instructing the model to summarize an English text in Spanish, it can be better to ask it to summarize the text in English first and only then prompt it to translate that summarization to Spanish. The reasoning behind this is simple: in its training data, most LLMs will have seen more examples of English-to-English summarization and English-to-Spanish translation than direct English-to-Spanish summarization. That is why they will often be better at the simpler tasks than at the complex one.
Rule 3: Describe the output length #
Unclear prompt
Summarize this document.
Clear prompt
Summarize this document in around 200 words.
Chatbots like ChatGPT are often very talkative, so it can be a good idea to specify the desired length of the response. Just don’t forget that LLMs, as we saw above, don’t excel at counting. And because they work with tokens rather than words, counting words is particularly challenging. This means that when you prompt them for a text of 100 words, the result will be close to that number, but it will not always be exactly 100. If you have a strict word limit, always check the result!
To illustrate this challenge, I did a very simple experiment. I asked GPT-4o, one of ChatGPT’s most capable models, first to write a text of 100 words and then to count the number of words in that text. Over 100 repetitions, its estimated word count varied between 88 and 114 words. The figure below shows that on average, the estimated counts were slightly below the expected 100. Admittedly, this simple experiment doesn’t tell us whether writing task or the counting task is at fault, but it does teach us not to trust an LLM when it comes to word counts.
The distribution of responses when you ask GPT-4o to write a text of 100 words and then have it count the number of words in that text.
Rule 4: Describe the output format #
Unclear prompt
What are the pros and cons of nuclear energy according to this document?
Clear prompt
Create a table with the pros and cons of nuclear energy based on this document.
Don’t forget that LLMs are not restricted to outputting running text. Sometimes it can be helpful to receive a more semi-structured prompt, in the form of bullet points, a numbered list or a table. If you want to integrate the result in a website or a programming project, you can ask for an html response, a structured file format like xml or json, and even programming code.
Rule 5: Ask multiple suggestions #
Unclear prompt
Suggest a good title for the blog post below.
Clear prompt
Suggest 20 varied titles for the blog post below that will make readers curious.
When you’re using an LLM for brainstorming, it can be advantageous to ask the model for multiple proposals rather than one. This improves the chances that you get a good suggestion straight away, and can also increase the variation between the individual suggestions.
Rule 6: Format your prompt #
As your prompt gets longer, it’s best to organize it with markdown and XML. Markdown is a simple markup language that can help you structure your prompt better through the use of headings (indicated by #) and lists (with items indicated by -), etc.
# Heading 1
## Heading 2
**Bold** and *italic* text
- Bullet list item
1. Numbered list item
[Link](https://example.com)
> Blockquote
`Inline code`
Similarly, xml tags like <example>...</example> or <quote>...</quote> can help delineate particular pieces of information in your prompt. Many LLMs were post-trained (in the second training phase) on data with markdown and xml tags, so they tend to handle this type of structured data well.
Rule 7: Continue the conversation #
There is a reason why ChatGPT is called Chat-GPT. The model is developed to engage in a conversation with its users, so when it responds to your prompt, it’s a good idea to continue that dialogue. You can ask the model to elaborate one of its suggestions in more detail, to combine multiple suggestions it has made, to rewrite a text it has just written, to expand a topic into a text structure and then into a text, and so on.