Choosing a Model #
There is no shortage of Large Language Models these days. ChatGPT, Claude, Gemini, Grok, Qwen, DeepSeek, Mistral and many others offer high-quality chatbots for many applications. It’s hard to give strong recommendations: the quality of a model often depends on the task and can also be a matter of personal preference. New models are released all the time, so today’s winner for a particular use case may be beaten tomorrow by a new kid on the block. Keep an eye on leaderboards like the LMArena if you want to find out what model currently scores best on tasks like coding, math or creative writing. So, rather than claiming ‘Gemini is best for creative writing’ or ‘Claude excels at code’, in this chapter I want to focus on a number of objective criteria that can help you make an informed decision when comparing LLMs.
Bigger is Better #
One of the most defining characteristics of an LLM is its size. This size is usually expressed as the number of parameters: the weights in their calculations that are tuned during training. Modern LLMs have billions of parameters. The smallest ones may have 2 or 3 billion, while the largest ones have hundreds of billions. The more parameters, the more “brainpower” a model has and the more knowledge it can store. This means that larger models will perform better on most tasks than smaller ones: they will give more accurate answers and hallucinate less often. Size also comes with a downside, however: because larger models need more computing power, they are slower and need more energy to train and run.
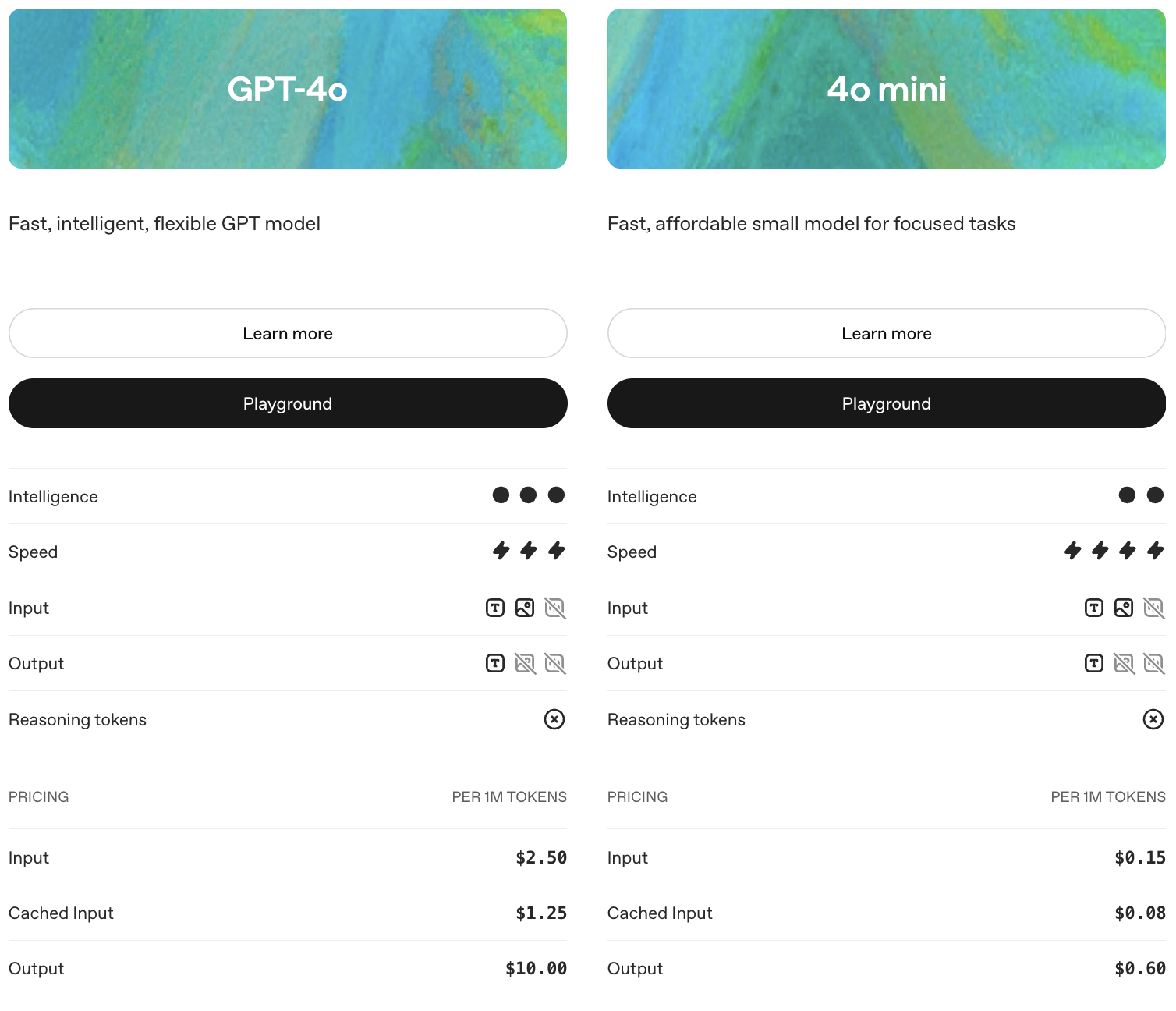
Many LLM providers offer both smaller and larger versions of their models. In ChatGPT, the smaller models all have ‘mini’ in their name. As the comparison below between GPT-4o and 4o-mini shows, the larger alternative is always smarter but slower, and (often many times) more expensive. When responses need to be factual and correct, the larger model usually presents the better choice. For simpler, less critical tasks, don’t hesitate to go for the more budget-friendly option.
The performance of OpenAI’s o1 model does not only improve with longer training (left) but also with time spent ’thinking’ (right).
(Source: OpenAI)
Open models #
Most popular LLMs are closed models. Chatbots like ChatGPT, Claude, Gemini and the like are easily accessible, but they keep their underlying language models private. This means we will never know exactly how they work, can only influence their behavior through prompting and need to share our data with their developers to use them. Open models, by contrast, put all their cards on the table. We can see their architecture, consult all their parameters, and even download them to our own computer to run them locally (provided it is powerful enough). Some teams even release the software that was used to train the model, making it truly open-source.
Some of the most well-known open models are the Llama family (developed by Meta, the company that owns Facebook), the Qwen family (by Alibaba), OpenAI’s GPT-oss, DeepSeek and some models by French company Mistral. Interestingly, Chinese companies play a remarkably active role in the development of open models. These don’t just allow them to grow their brand, but also an ecosystem of developers that build applications on top of them.
Software like Ollama allows you to chat with LLMs on your own computer.
Many open models are available for download from the Hugging Face Hub. You don’t even need to be a programmer to use them! Software like Ollama is simple to install on a home computer and allows you to chat with a variety of (small) open LLMs. Although these small models do not offer the performance of their larger competitors, you don’t need an internet connection to run them and your data never leaves your computer.