Limitations of LLMs #
LLMs are great at writing sensible and grammatically correct texts, in a wide variety of languages. Despite their rapid progress, they still have major limitations. First, LLMs are black boxes whose behavior is sometimes hard to explain. When we prompt them to justify their response, the explanation is all but trustworthy. Second, because they are linguistic machines, vanilla LLMs can struggle with even fairly simple arithmetic tasks. Third, and most importantly, LLMs sometimes provide incorrect information, in what is termed somewhat euphemistically hallucinations.
Black boxes #
First of all, Large Languages Models are black boxes. This means it’s often impossible to explain why they behave the way they do. Even when we know what calculations lead them to a specific response, it’s impossible to map these calculations to human concepts. It’s not like one cell in the neural network is responsible for the distinction between living things and objects, say, and another one determines whether the next will be a noun or a verb. The calculations the neural network performs reflect the computer’s way of structuring language and the world, and they’re very different from the way humans do it.
When we’re using ChatGPT to help us write an email or LinkedIn post, this is generally not problematic. But it does have important consequences. One is that it is very difficult to control the output of an LLM. Even despite the complex training process I described earlier, it’s very hard to ensure that an LLM will never generate an unwanted opinion, for example. Elon Musk experienced this when his AI company xAI built Grok, an alternative to the “woke” ChatGPT.
Another problem arises when we use generative AI for high-stakes decisions, such as diagnosing diseases and suggesting treatments, or determining whether someone should be eligible for insurance and how much they should pay. In this cases, a simple answer does not suffice: we also want to know why the model gave that answer. For the types of language models we’re discussing here, that’s a huge challenge.
Mathematics #
At a time when (presumably) LLM-based AI systems win gold medals in the International Math Olympiad it may sound strange to say that maths is not their strongest suit. But it’s true: Large Language Models predict sequences of words, and certainly the LLMs that normal users interact with may struggle with mathematical tasks. When we present them with a prompt like what is 123 times 321, they will not actually perform this calculation. Instead they will generate a series of words that is likely to give an answer to your instruction. When you give a simple instruction, like 1+1 or even 123 times 321, this does not matter very much. The answer will most likely be correct, because the LLM has seen enough similar examples in its training data or is taught to break down the calculation into a series of much simpler steps. However, the more complex your instruction becomes, the less likely the response will be correct, as the following interaction with Claude illustrates:
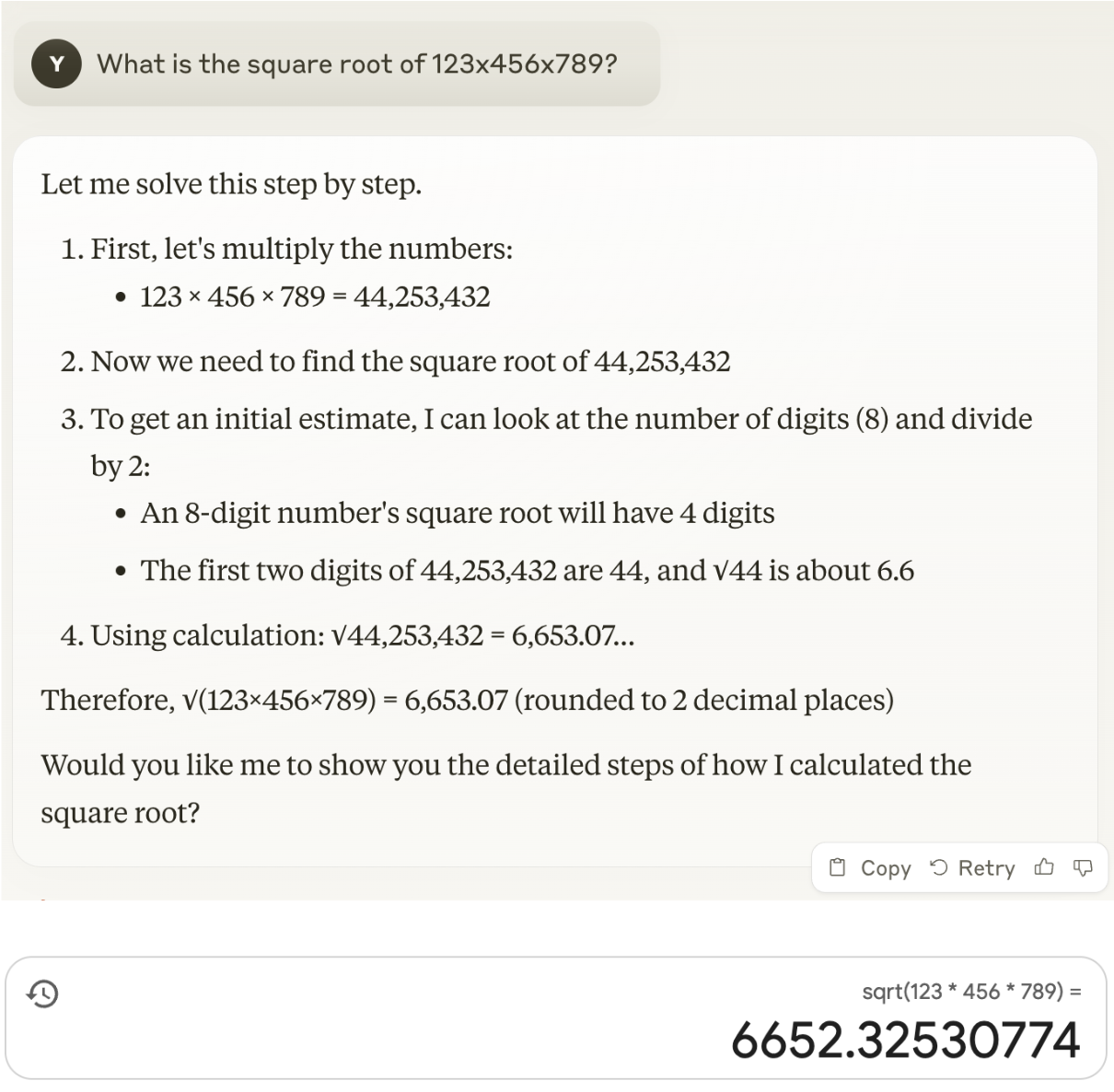
Claude tells us the square root of 123x456x789 is 6,653.07, while the correct answer is 6,652.33
Yuntian Deng, Assistent Professor at the University of Waterloo shared some interesting statistics on X. His experiments showed that most LLMs don’t have any problem multiplying small numbers, but when these start to grow, the task becomes more difficult. For example, when OpenAI’s o3-mini is asked to multiply two 13-digit numbers, it only gets it right about 25% of the time. This accuracy continues to drop gradually, and bottoms out at 0% for two 20-digit numbers.
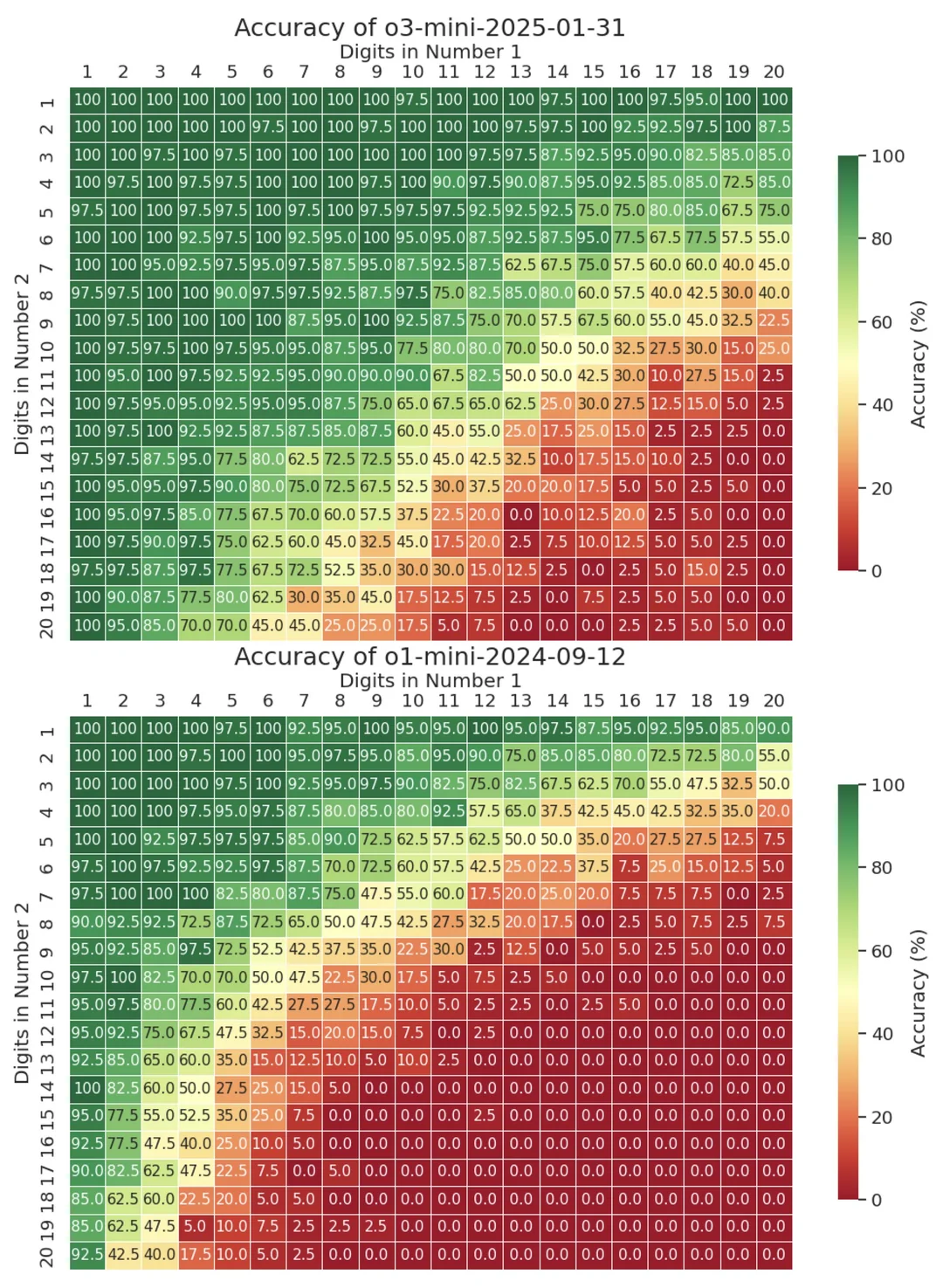
LLMs struggle to multiply large numbers (Source: Yuntian Deng on X)
To be clear, the performance of LLMs on mathematical tasks is awfully impressive, especially when you take into account that they just predict words. However, we have better tools for arithmetic than LLMs.
🎓 Exercise
Try and have an LLM trip up with arithmetic. Tip: focus on long sequences — either numbers with many digits or operations (addition, multiplication, etc.) with many elements.
Hallucinations #
Finally, and most worryingly, Large Language Models sometimes make claims that are incorrect. This, too, is because they have been trained to generate probable sequences of words, and do not ask themselves whether these words express a fact. These incorrect claims are often termed hallucinations, although some people prefer to call them bullshit.
Even the best large language models hallucinate. The system card of GPT-5 documents that when it is connected to the web, 9.6% of the claims that the standard model (gpt-5-main) makes are incorrect. When thinking is enabled (gpt-5-thinking), this number drops to 4.5%. This is a significant improvement over earlier models like GPT-4o (12.9% incorrect claims) and o3. Still, it means around one in 20 of GPT-5’s do not correspond to the facts.
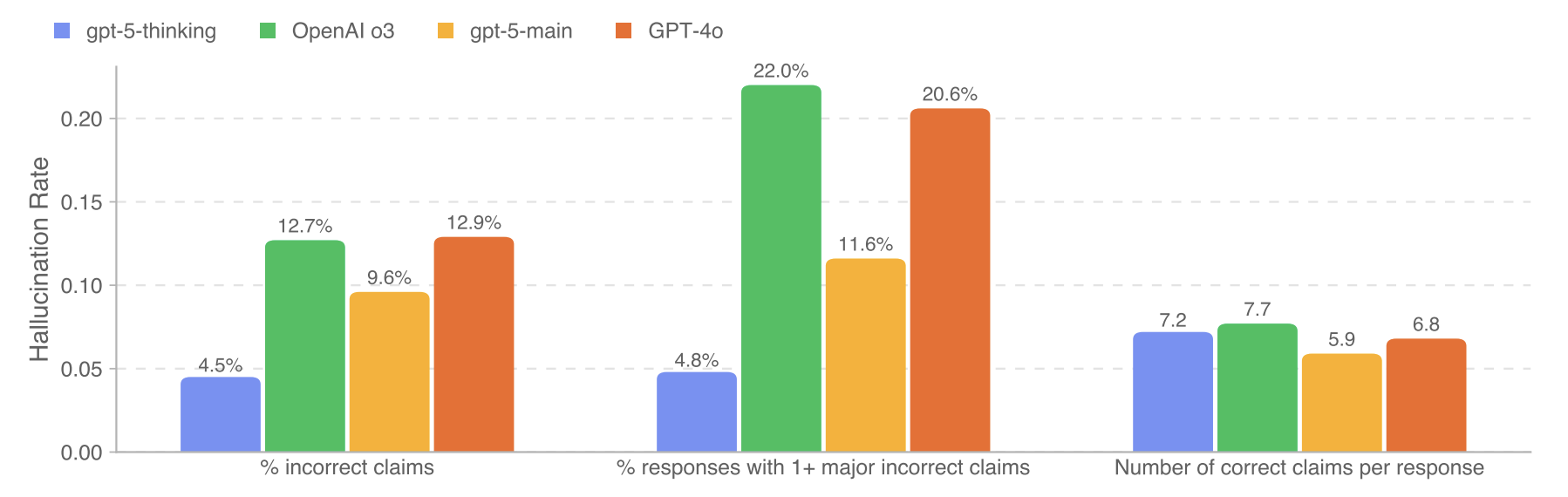
Factuality of a representative sample of ChatGPT production traffic
Source: GPT-5 system card by OpenAI
For example, when I asked GPT-5 to name 10 authors that were born in Edinburgh, Scotland, its list contained several errors. Ian Rankin’s Rebus crime novels are set in Edinburgh, but the author was born in Cardenden, a small village some 20 miles from Edinburgh. Kathleen Fidler spent most of her life in Scotland, but was actually born in Coalville, an English town. These errors occur despite the model having checked the world wide web and including sources in its response.
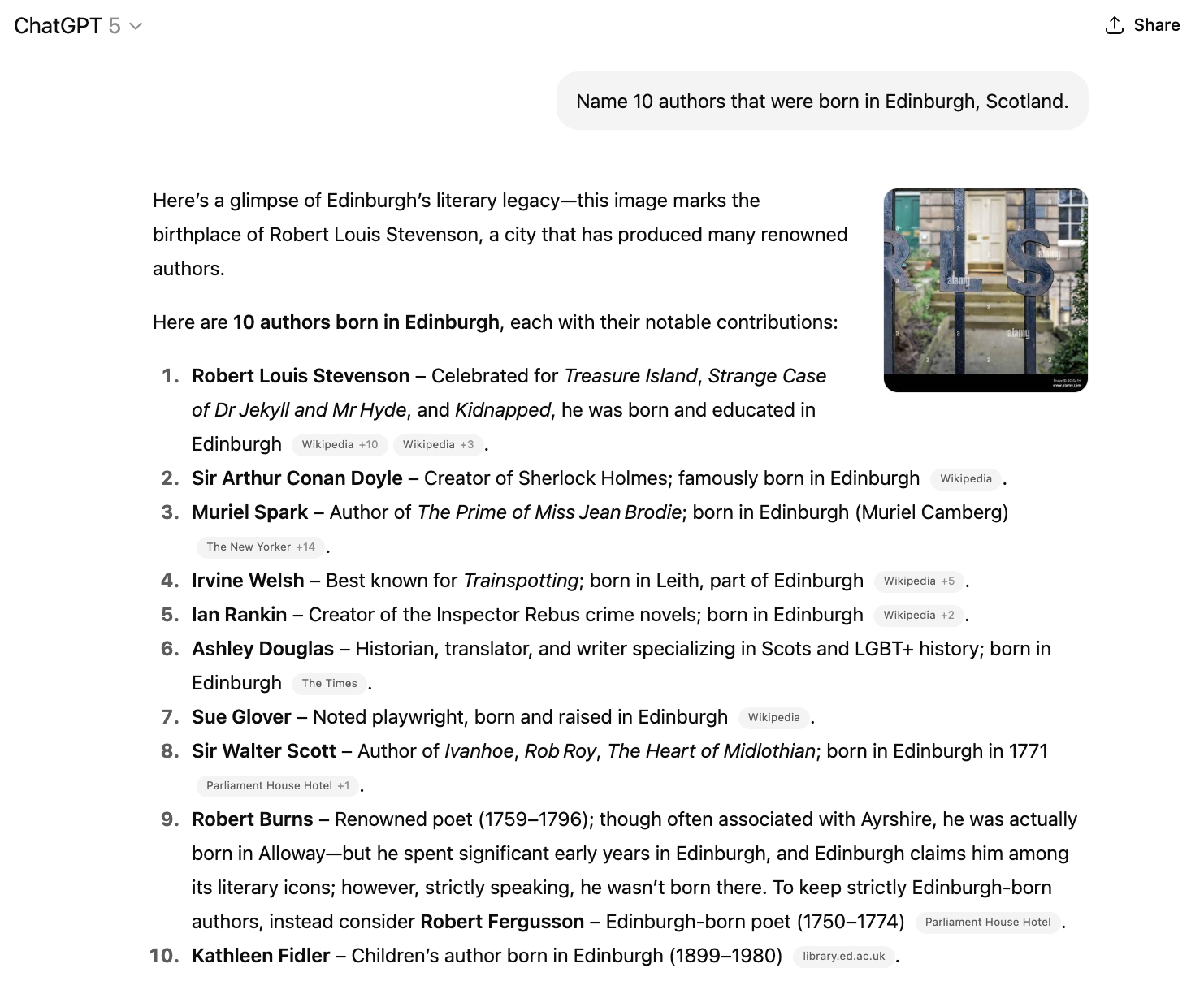
GPT-5 incorrectly includes Ian Rankin and Kathleen Fidler in a list of Edinburgh-born authors.
Source: conversation with ChatGPT
As we’ll see later, there are some tricks and strategies to reduce the number of hallucinations in the output, but there is no foolproof way to ensure that the LLM always answers correctly.