Reasoning models #
During the first years of LLM development, the largest quality improvements originated from scaling up the training data. However, this strategy eventually met its limits, as the amount of available, unused data was shrinking fast. Even more worryingly, an increasing percentage of new texts had been generated by the LLMs themselves, which could lead to a collapse of new models. As a result, developers had to find other ways of improving the output of their models. They found a solution in so-called “reasoning” traces.
Chain-of-thought prompting #
The origin of reasoning models lies in chain-of-thought prompting, a prompting strategy that proved very effective for the first generation of LLMs. In chain-of-thought promptingm (Wei et al. 2022), LLMs are instructed to generate intermediate reasoning steps before they give the final answer to a question. This was found to lead to much more accurate responses.
Let’s look at an example. Suppose you give a vanilla language model an arithmetic task like this:
The cafeteria had 23 apples. If they used 20 to make lunch and bought 6 more, how many apples do they have?
If the LLM immediately formulates an answer, there is a good chance this is incorrect. This is because answering this question requires multiple calculations. First 20 must be subtracted from 23, and then 6 must be added to the intermediate result. Therefore we’d like to prompt the LLM to work in steps rather than jump to the final answer straight away.
This can be achieved in two ways. Wei et al. 2023’s original solution is to include a similar
example in the prompt with a response that includes such reasoning steps. In this way, the language model is primed to react
to a new task in the same vein. Instead of writing The answer is 27, it might now generate the following reasoning chain, which leads to the
correct result:
The cafetaria had 23 apples originally. They used 20 to make lunch. So they had 23-20=3. They bought 6 more apples, so they have 3+6=9. The answer is 9.
Their paper shows that his behavior can lead to large jumps in accuracy, not just for arithmetic, but also for commonsense and symbolic reasoning tasks.
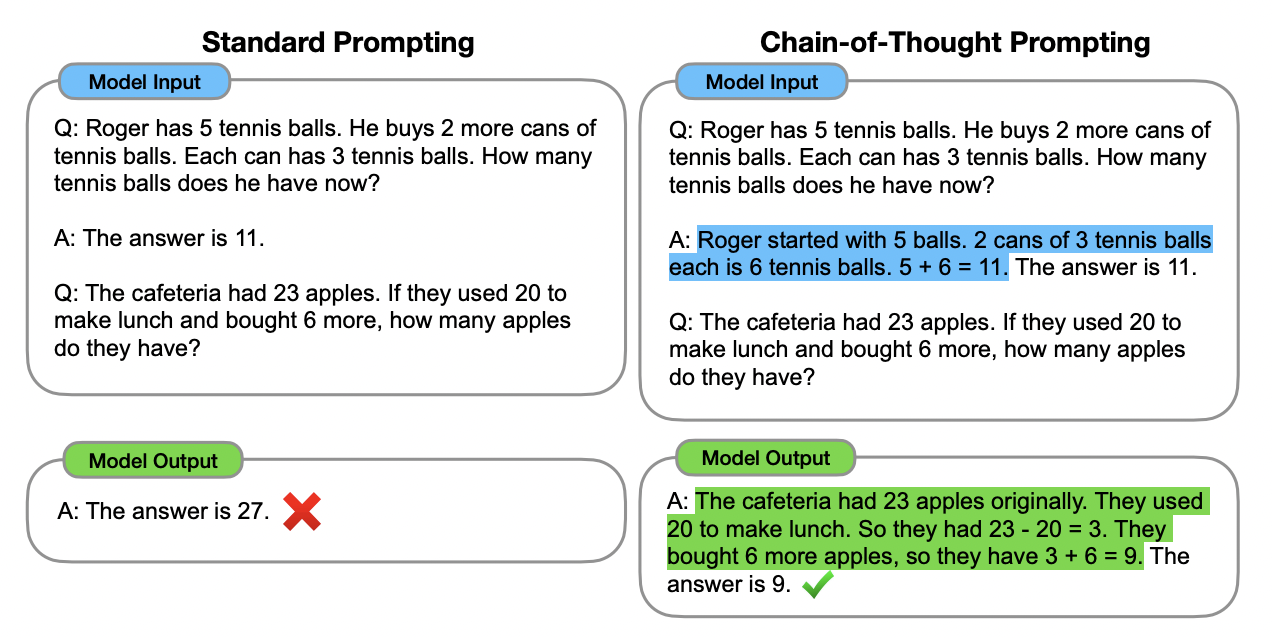
Chain-of-thought prompting triggers language models to generate intermediate reasoning steps before giving their final answer (from Wei et al. 2022).
A second, simpler way to trigger this “reasoning” behavior is to simply prompt an LLM to think step by step. Even this simple extension of your prompt can already lead to more accurate answers. For example, it is well-known that non-reasoning models like GPT-4o often have problems counting the number of letters in a word, like the number of r’s in cranberry. Prompting such a model to think step by step often fixes this problem:
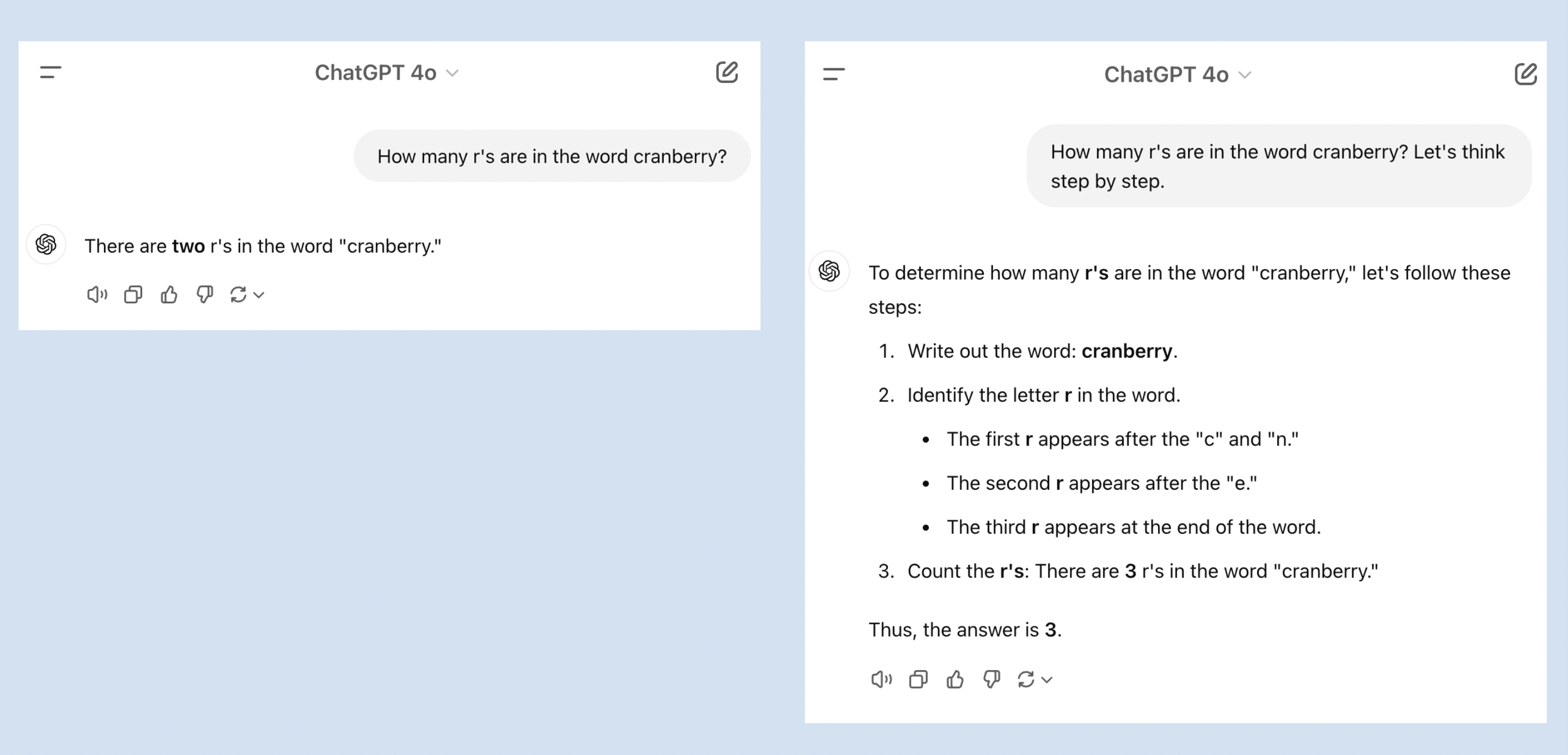
Merely adding ‘Let’s think step by step’ to your prompt can already lead to more accurate answers.
From prompting to training #
More than any other prompting technique, chain-of-thought prompting has shaped the development of LLMs. Initially, developers added chain-of-thought instructions to the system prompts of their chatbots. These system promts are the prompts with which every conversation starts, but that remain invisible to the user. For example, the system prompt of Claude-3.5-sonnet contained the following instruction:
When presented with a math problem, logic problem, or other problem benefiting from systematic thinking, Claude thinks through it step by step before giving its final answer.
This update to Claude’s system prompt meant that individual users didn’t have to spell this out in their own prompts anymore.
But the change didn’t stop there. LLM developers also started incorporating reasoning traces in the training regime of their LLMs, explicitly training the models to output long chains of thought. These often contain hundreds or thousands of words and allow models to break down complex tasks into smaller steps, revise their solution and explore alternative paths. Experiments showed that model accuracy on challenging tasks like math and programming improved dramatically with the length of their reasoning traces — or, more informally, the time the models spend “thinking”, not just during training, but also during actual usage:

The performance of OpenAI’s o1 reasoning model does not only improve with longer training (left) but also with time spent ’thinking’ during usage (right).
(Source: OpenAI)
How do these models learn to “think”? Typically this is done with several carefully crafted training datasets. The first dataset is a “cold start” set of manually curated prompts and responses with a reasoning trace. Because this dataset is far too small to lead to robust performance, models then continue to train more autonomously: they are allowed to come up with their own reasoning traces, after which the final solution is checked. If the solution is correct, the reasoning trace gets a boost; if it is incorrect, the reasoning is penalized. This learning strategy is called reinforcement learning. Its automatic checking process means reasoning models are mainly optimized mainly for verifiable tasks like math and programming, where it is fairly easy to validate an answer. Additionally, humans give feedback on examples that are not so easy to verify automatically, by ranking them from better to worse. Through this combination of manual and automatic feedback, LLMs can learn to reason in a consistent manner.
Examples of reasoning models #
One of the most well-known reasoning models is DeepSeek’s R1 model, which caused quite a stir when it was first released. Not only did it show that China had all but caught up with the US in artificial intelligence; DeepSeek’s models had also been far cheaper to train than many of their competitors. To see a concrete example of a reasoning trace, let’s ask R1 to write a haiku on artificial intelligence. As the video below shows, it first recalls what a haiku is and then explores some potential themes (like learning, data or algorithms). After that, it generates a draft line by line, which it checks fo content as well as syllable count. Only when that is all done does it return the final haiku.
The accompanying paper also gives an interesting peak into how reasoning models are trained. For example, it shows that as its accuracy improved during its training process, the length of the reasoning traces also went up. This suggests that longer reasoning traces go hand in hand with higher quality.
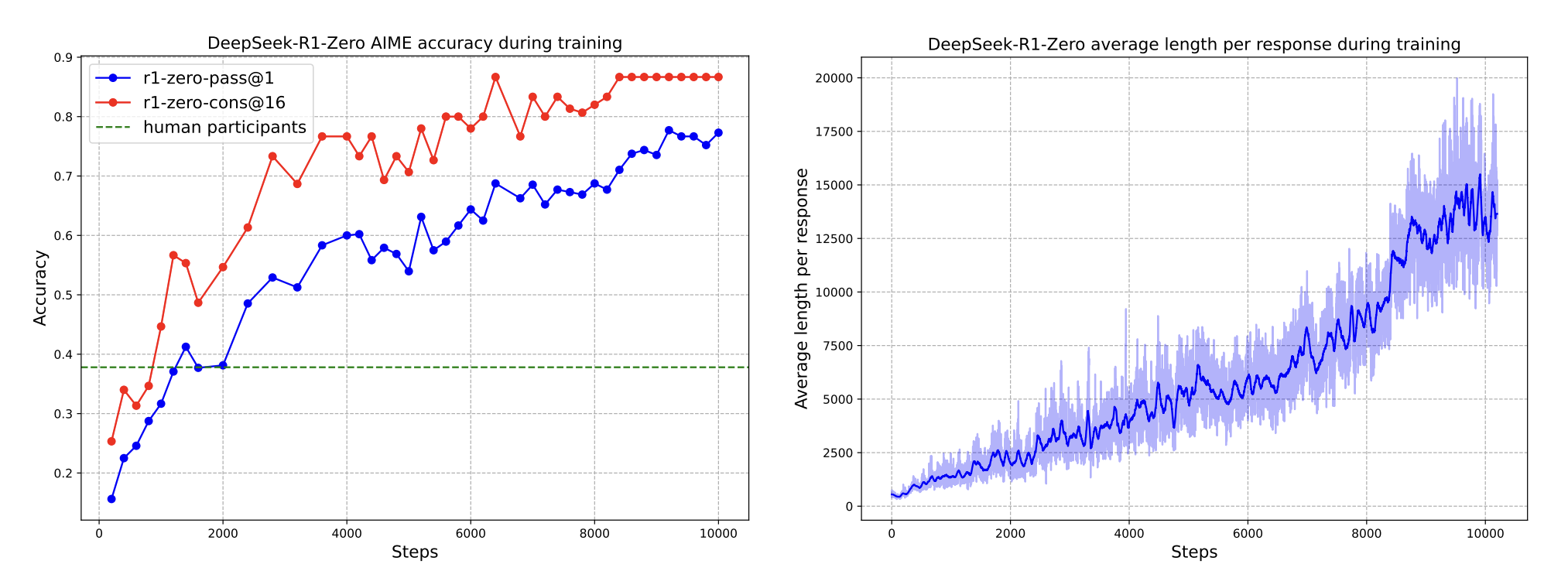
During the training process, the length of Deepseek’s reasoning traces increased steadily.
As the reasoning traces grew, the DeepSeek team noted that the model also started to sound more human-like. For example, they found that the word wait started to occur more often, typically in examples like the one below, where the model stopped to think and re-evaluate its reasoning process. This shows the strength of reinforcement learning, where models are not trained to reconstruct a text word by word, but are allowed to come up with their own reasoning strategies, as long as they lead to the correct solution.

Deepseek’s reasoning model taught itself to re-evaluate its reasoning in a very human-like manner.
Many models today are hybrids between standard and reasoning LLMs. GPT-5, for example, doesn’t always use its reasoning capabilities. It has an internal router that considers every prompt and decides whether to “reason” or not. Claude’s Sonnet and Opus models also feature reasoning capabilities, as do Google’s Gemini Flash and Pro. Most providers also allow users to control the length of reasoning traces, to find the best balance between cost, quality and speed, although this is often only available to developers that integrate the models through their API.
GPT-5 has an internal router that considers our prompt and decides whether to ‘reason’ or not.
When to use reasoning #
Many current chatbots let you choose between a heavy reasoning model and a faster standard model. When you make that choice, it’s good to keep in mind that reasoning does not necessarily help with all types of problems. OpenAI’s early experiments with their o1 model indicated that users tend to prefer o1 (reasoning) to GPT-4o (non-reasoning) for challenging tasks like computer programming, data analysis and mathematical calculation, but not for more language-oriented tasks such as personal writing and editing text. This may be a result of the training process, which is focused on verifiable tasks such as math problems, but it may also mean that tasks of a more textual nature require a different approach.
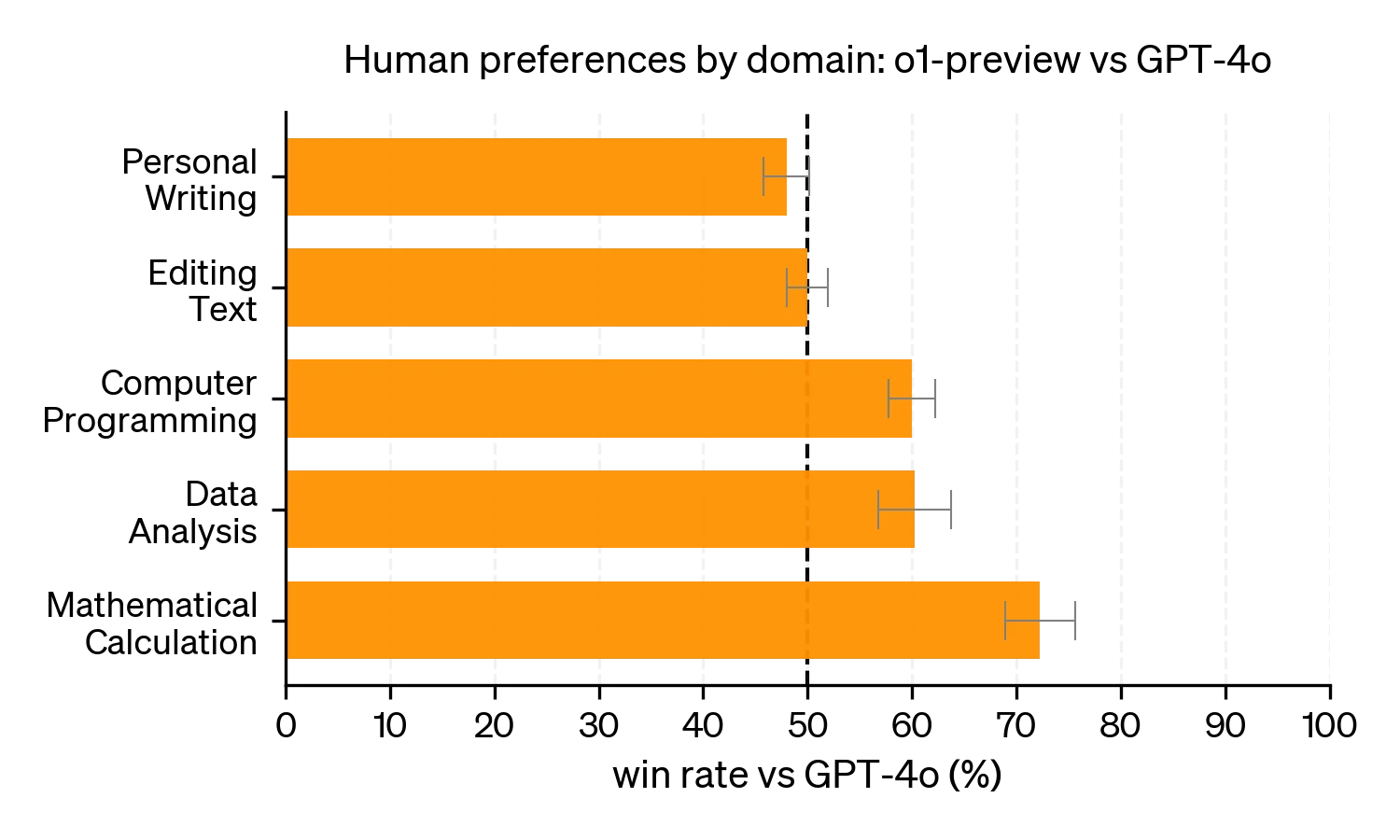
Users tend to prefer o1 to GPT-4o for challenging tasks like math and programming, but not for more language-oriented tasks.
(Source: OpenAI)
In general, it’s best to choose a reasoning model for complex tasks, like logical problems, advanced mathematics or porgramming tasks, where accuracy is important. Vanilla LLMs may work better for simpler tasks, tasks that you can define well in advance, and when you need high speed or low costs.
Prompt engineering for reasoning models #
Start simple #
Many problems don’t require lengthy reasoning traces. Therefore it’s best to start with limited reasoning and scaleit up when this is required by your type of problem. If you use an LLM through an API, there is often a parameter like reasoning_effort that allows you to vary the length of its reasoning traces. Similarly, you can increase the reasoning effort through prompt engineering, by adding instructions like “think hard about this”, “consider alternative viewpoints”, or similar.
Give reasoning examples #
If you know the type of reasoning the model should use to perform your task, it can be helpful to give one or more examples of similar tasks with the reasoning traces included. Place these traces between <thinking> tags, so that the LLM knows they are not part of the final answer. Let’s take the mathematical problem from the chain-of-thought paper as an example:
Non-reasoning LLM
Q: Roger has five tennis balls. He buys 2 more cans of tennis balls. Each can has three tennis balls. How many tennis balls does he have now?
A: Roger started with 5 balls. 2 cans of 3 tennis balls each is 6 tennis balls. 5+6 = 11. The answer is 11.
Q: The cafetaria had 23 apples. If they used 20 to make lunch and bought 6 more, how many apples do they have?
Reasoning LLM
I’m going to show you how to solve a math problem, then I want you to solve a similar one.
<example>Problem 1: Roger has five tennis balls. He buys 2 more cans of tennis balls. Each can has three tennis balls. How many tennis balls does he have now?
<thinking>Solve this problem step by step:
- Roger started with 5 balls.
- 2 cans of 3 tennis balls each is 6 tennis balls.
- 5+6 = 11.
</thinking>The answer is 11.
</example>Now solve this one:
Problem 2: The cafetaria had 23 apples. If they used 20 to make lunch and bought 6 more, how many apples do they have?
Give more freedom #
However, in many cases it’s difficult to spell out the exact reasoning the LLM should follow. Moreover, since reasoning models were mostly trained on examples of reasoning they created themselves, it is possible that they come up with original reasoning paths that we cannot anticipate, or alternative reasoning paths that work better than our own. That’s why in contrast to standard LLMs, for reasoning models it’s usually best to stay away from all too detailed steps in your prompt. Instead keep your instructions general and let the model choose the optimal reasoning path itself. Encourage it to consider multiple approaches, verify its answers and try different methods if the first approach didn’t work.
Non-reasoning LLM
Think through this math problem step by step:
- First, identify the variables
- Then, set up the equation
- Next, solve for x
…
Reasoning LLM
Please think about this math problem thoroughly and in great detail. Consider multiple approaches and show your complete reasoning. Try different methods if your first approach doesn’t work.
Define test cases #
Another good practice is to present a reasoning model with concrete test cases to practice its results. This makes it easier for the LLM to check its solution, and correct it when necessary by backtracking, exploring different reasoning paths, etc.
Vague prompt
Write a function to calculate the factorial of a number.
Improved prompt
Write a function to calculate the factorial of a number.
Before you finish, please verify your solution with test cases for:
- n=0
- n=1
- n=5
- n=10
And fix any issues you find.
Let’s not antropomorphize #
You may have noticed my frequent use of quotation marks in this chapter. This is because it’s important to stress that reasoning models don’t really think or reason — they just generate intermediate words that break down a complex task into simpler steps. So when ChatGPT informs us that its model thought for 1 minute 57 seconds, it was mindlessly writing rather than thinking. Indeed, researchers from Arizona State University urge everyone to Stop Anthropomorphizing Intermediate Tokens as Reasoning/Thinking Traces, arguing that casting this process as thinking “is actively harmful, because it engenders false trust and capability in these systems, and prevents researchers from understanding or improving how they actually work” (p.9).
Indeed, the team at Anthropic reported that Reasoning Models Don’t Always Say What They Think (Chen et al. 2025). To test the faithfulness of reasoning traces, they presented Claude Sonnet and DeepSeek-R1 with a set of multiple choice questions, both with and without a hint included in the input. These hints could take various forms: sometimes the correct answer could be inferred from a visual cue (e.g., a tick mark); other times the prompt included an answer suggestion (e.g. A Stanford professor indicates the answer is A) or the correct answer had appeared earlier in the conversation. In all cases, both Claude and DeepSeek-R1 showed a tendency to follow this hint — yet their verbalized reasoning processes rarely acknowledged doing so. While reasoning models were considerably more “honest” than standard LLMs, their explanations were faithful in just 25% (Claude) and 39% (DeepSeek) of the cases. Interestingly, the researchers also observed that unfaithful explanations were typically longer than faithful ones, and that models were less likely to admit using a hint when the question was more difficult or when the hint was presumably obtained in an unethical way (e.g., when the prompt mentioned unauthorized system access). In other words: do use a reasoning model for complex tasks, but treat its “thinking” with suspicion.
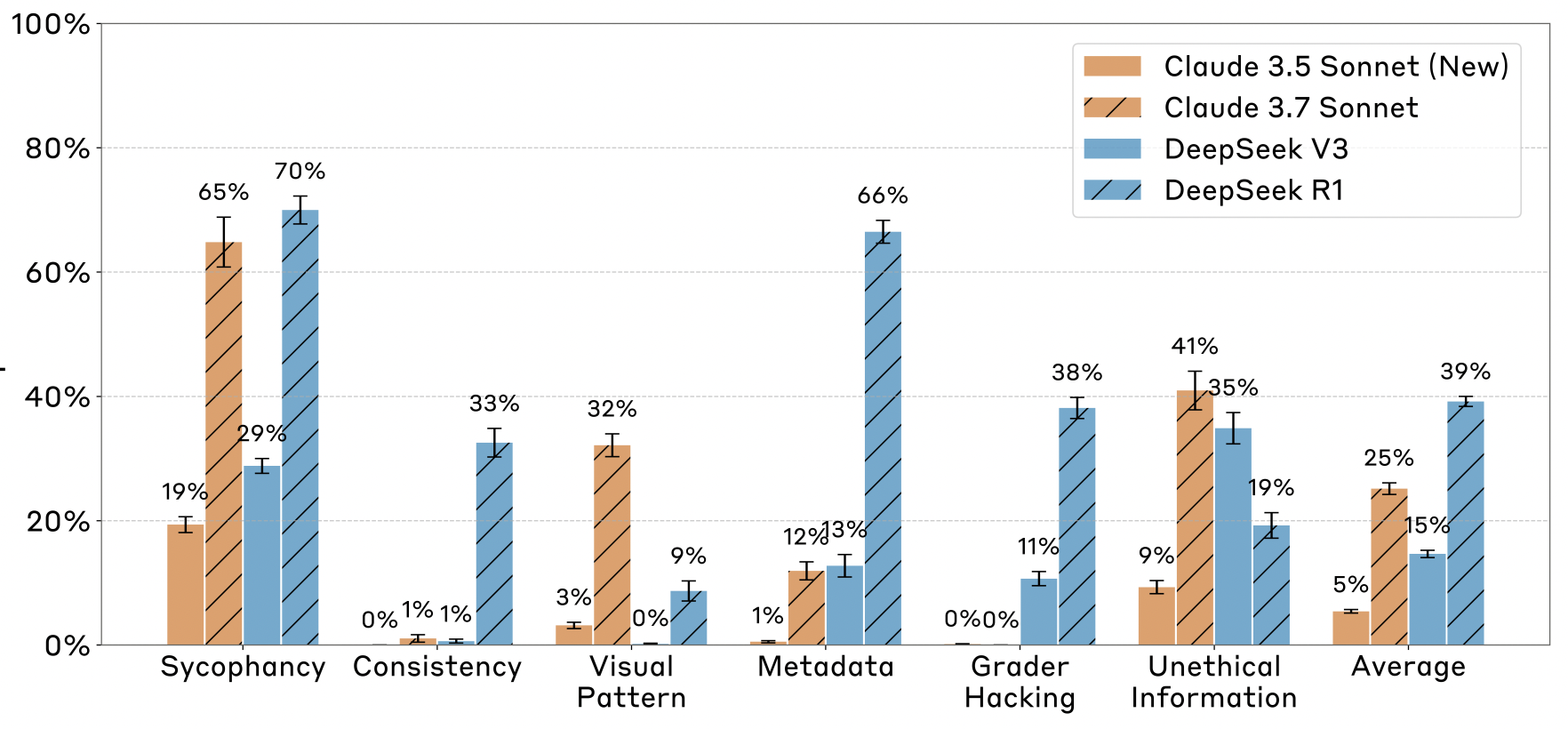
The percentage of faithful explanations (referring to the hint) for 4 models and 6 types of hints. Source: Chen et al. (2025)
The same observation is true for chains of thought returned by standard LLMs, too. For example, Turpin et al. (2023) showed that LLMs are sensitive to bias in the prompt when they answer multiple choice questions: when the first answer is the correct one for all example questions in the prompt, models are typically triggered to select the first answer for a new question as well. When they’re asked to provide their chain of thought, however, they “rationalize” their choice and give a completely different explanation.
Our earlier example, where we prompted a model to count the number of r’s in the word cranberry also illustrates why we shouldn’t put too much confidence in chains of thought. In its second step, GPT-4o claimed that the first r appears after the c and n, which is clearly not true: it appears after the c but before the n. This illustrates that even when the intermediate steps are not always reliable, on average they do lead to more accurate answers.