Reducing Hallucinations #
The biggest headache for users of Large Language Models is the risk of hallucinations. When you’re writing a poem, you need not worry about them, but in almost all other contexts, you want the answer of the LLM to be factually correct.
Eliminating hallucinations is one of the holy grails of language modeling. So far, no technique has been shown to bring the risk of incorrect claims to zero. There are some methods, however, that we can use to reduce their number.
Parametric Knowledge and External Sources #
When you’re concerned about hallucinations, the single most important question to ask is where the language model gets its information from. LLMs are most prone to hallucinating when they use their parametric memory: the statistics they have learned while they were trained to predict the next word in a sequence. During their initial training stage, the factuality of the generated word sequence was never part of the equation. You could argue that it is more a byproduct of the initial training than its explicit goal: it merely follows from the situation that the training data contains more correct than incorrect information.
Let’s return to the Transformer Explainer from our introduction to LLMs. If we enter the words Barack Obama was born on, the language model behind the explainer will identify the most probable next words. Although these are all months, the model is not able to conclusively identify the correct one: April has the highest probability (11.96%), followed by January (10.05%) and March (9.20%). As it continues the sentence, the model will choose one month from the top candidates, but chances are low it will select the correct one, August (3.95%). Either it hasn’t seen enough relevant data during its training, or it didn’t have sufficient parameters to learn the link between Barack Obama and his month of birth.
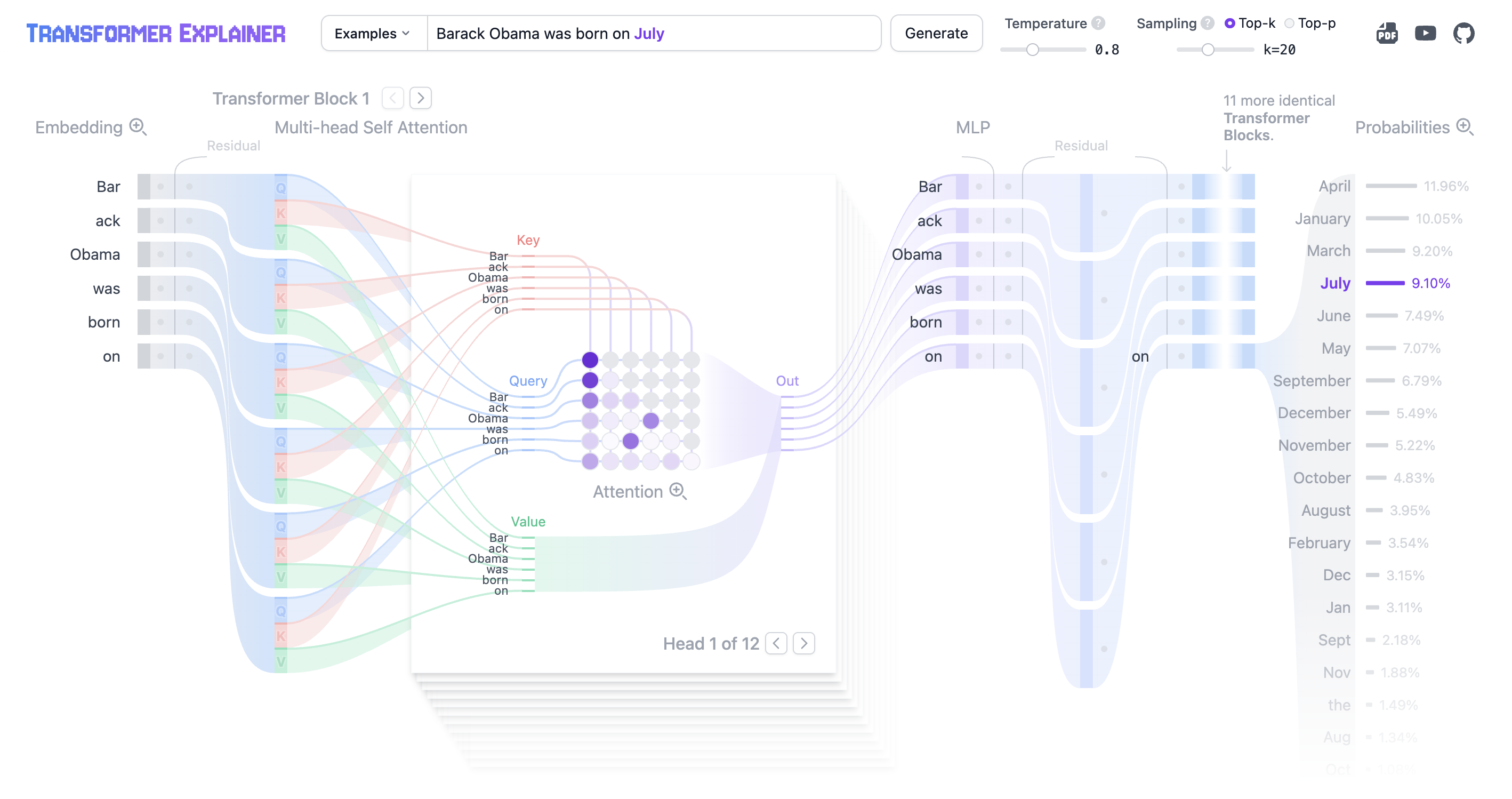
Large Language Models are neural networks that predict the next word in a sequence (Source: Transformer explainer).
The situation changes when we give the model access to a source that contains the answer to our question. This can be a document or a vast resource like the world wide web. In this case, the LLM doesn’t have to reconstruct the relevant facts from its parametric knowledge. It merely needs to locate the answer in the documents and then reuse it in its response. You can compare this to the difference between a closed-book and an open-book exam: in the latter, the real challenge lies in finding the correct information. Once this has been done successfully, the task becomes much easier.
This distinction shows up clearly in the benchmarks that LLMs are evaluated on. In the model card of GPT-5, OpenAI reports that when browsing is disabled, GPT-5’s reasoning model achieves a hallucination rate of 3.7% on FActScore, a benchmark with biographies of notable people (p. 12). With browsing, this hallucination rate further drops to just 1% (p. 11), which means that only 1% of its claims were incorrect.
Tool usage #
From the discussion above, it follows that the simplest way to reduce the number of hallucinations, is to ensure your chatbot can browse the world wide web or one or more relevant documents. However, there are other tools, too, that can increase the quality of the responses, certainly for specific tasks like arithmetic.
Documents #
Tip: Give the LLM access to documents with relevant information
One way to reduce the frequency of hallucinations, is to give the model a reliable source to consult. Many chatbots, like ChatGPT and Claude, allow users to upload a file and ask questions about it. Some can even be connected to a cloud service like Google Drive or OneDrive and read all the files users have stored there. Providing the model with one or more such reliable sources reduces the number of hallucinations, but does not bring it down to zero. It is still essential to check all important information.
The World Wide Web #
Tip: Prompt the model to search the world wide web.
For a lot of tasks, the ultimate source of information is the world wide web. In fact, whenever we give it a prompt for which ChatGPT considers its parametric knowledge insufficient, it decides to consult the web. This means that it will build a search query from your prompt, submit it to a search engine, read the most relevant results, and then compile its answer from those results. This again increases the chances that this answer is correct. If ChatGPT’s parametric knowledge does not allow it to predict, say, someone’s date of birth with a sufficiently high degree of confidence, it often decides to search the world wide web for any sources, like Wikipedia, that have this information and take it from there. Unfortunately this method is not foolproof: sometimes it misjudges its own knowledge, continues without any helplines and produces incorrect information. In those cases you can explicitly prompt it to ‘use the world wide web’. Even then, however, you can never be 100% certain the answer is correct.
The problem is that many of today’s models are not linked to a search engine. Many of the younger models like DeepSeek, for example, do not have this capability and always rely on their parametric knowledge only. This also goes for the open-source models you can download on your own computer, unless you connect them with the necessary tooling yourself. This means their answers will contain far more hallucinations than those of models capable of web search. If you’re doing research of any kind, it is therefore advisable to use a model that has access to the web, like ChatGPT or Copilot.
Programming code #
Tip: Ask the model to generate programming code instead of text
We’ve seen before that large language models struggle with mathematics and don’t actually perform the calculations we ask them to do. Luckily some chatbots have a solution to that. Whenever we give them a complex calculation that they are unlikely to answer correctly with their word prediction capabilities, they switch to another strategy. In these cases, rather than producing natural language, they will decide to generate the programming code for your calculation in a programming language like Python. Next, they run this programming code and build a response on the basis of the answer. When ChatGPT does this, you’ll see a short message that it is Analyzing your instruction. Behind the answer, there will also be a small icon that you can click to see the programming code. As with the internet search above, this strategy greatly increases the probability that the result is correct. The only risk is that ChatGPT may not have generated the right code — which for straightforward arithmetic instructions is very small.
Prompting Strategies #
Basic strategies #
Tip: Prompt the model to say “I don’t know” when it doesn’t have enough information.
A first way to minimize the chance of hallucinations is to explicitly allow the model to say “I don’t know” when it doesn’t have enough information to answer a question. Simply adding these words to your prompt increases the probability that the LLM will make use of them itself. In the prompting guide by Anthropic, we find the following example prompt that asks Claude to analyze a report:
As our M&A advisor, analyze this report on the potential acquisition of AcmeCo by ExampleCorp.
<report> {{REPORT}} </report>
Focus on financial projections, integration risks, and regulatory hurdles. If you’re unsure about any aspect or if the report lacks necessary information, say “I don’t have enough information to confidently assess this.”
Tip: Ask the model to provide a supporting quote.
If the LLM has access to relevant documents or the world wide web, another helpful strategy is to have it extract quotes that support its answer. You can choose to have the LLM first extract the quote and then base its answer on it, or first have it answer your question and then find a quote to support its claims. Here’s another example from Anthropic:
As our Data Protection Officer, review this updated privacy policy for GDPR and CCPA compliance.
<policy> {{POLICY}} </policy>
Extract exact quotes from the policy that are most relevant to GDPR and CCPA compliance. If you can’t find relevant quotes, state “No relevant quotes found.”
Use the quotes to analyze the compliance of these policy sections, referencing the quotes by number. Only base your analysis on the extracted quotes.
Consistency Prompting #
Tip: Take the most frequent answer from multiple responses.
We’ve seen before that LLMs are not deterministic: when we repeat our question, they (almost) always give a different answer. Advanced users can influence this degree of variation with multiple parameters, like temperature or top k, which are available in tools like OpenAI’s Dashboard. In more creative tasks, it’s often desirable to aim for higher variation, while in other ones, we actually want lower variation.
Self-consistency (Weng et al. 2022) is based on the intuition that tasks that require deliberate thinking typically have multiple reasoning paths to the correct answer. First, it uses chain-of-thought prompting to have the model generate intermediate reasoning steps before it gives the answer. Second (and in contrast to traditional chain-of-thought prompting), it has the language model generate many different responses. Finally, it selects the most frequent answer from these responses.
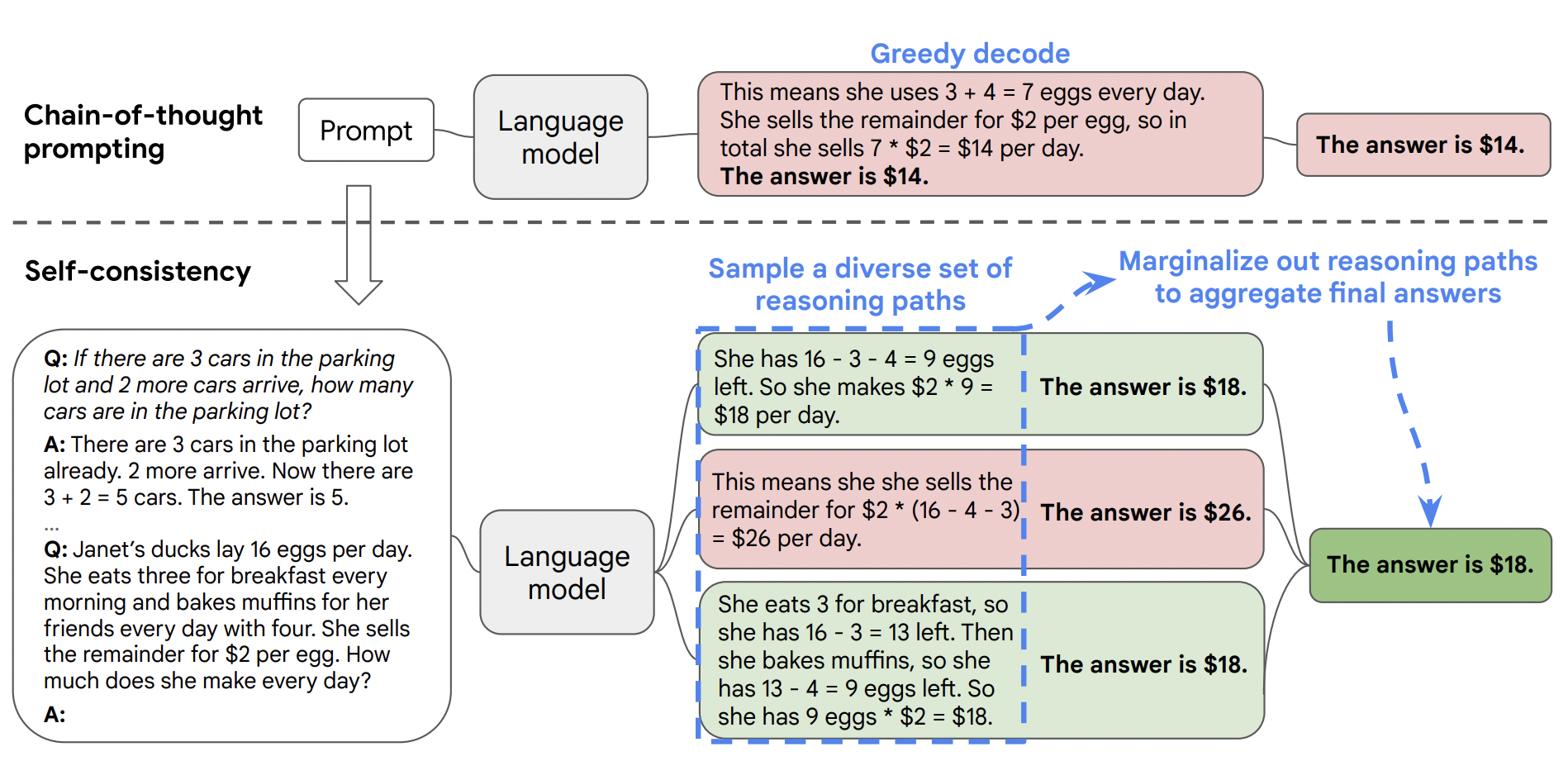
Self-consistency selects the most frequent answer from multiple chain-of-thought responses.
(Source: Weng et al. 2022)
Weng et al.’s experiments on a range of datasets show that with as few as five reasoning paths, the accuracy of the most frequent answer significantly exceeds that of the single-answer chain-of-thought paradigm. The more reasoning paths are sampled, the further the accuracy improves.

Self-consistency leads to more accurate answers than traditional chain-of-thought prompting.
(Source: Weng et al. 2022)
Verification Prompting #
Tip: Have the LLM factcheck its own response.
Another way of reducing hallucinations is to make use of automatic verification strategies. One such popular strategy is chain-of-verification prompting (Dhuliawala et al. 2023), which takes advantage of the fact that the “knowledge” of a model may vary with the prompt. For example, although a model may know the mother of Céline Dion, it might not know the daughter of Thérèse Tanguay’s daughter.
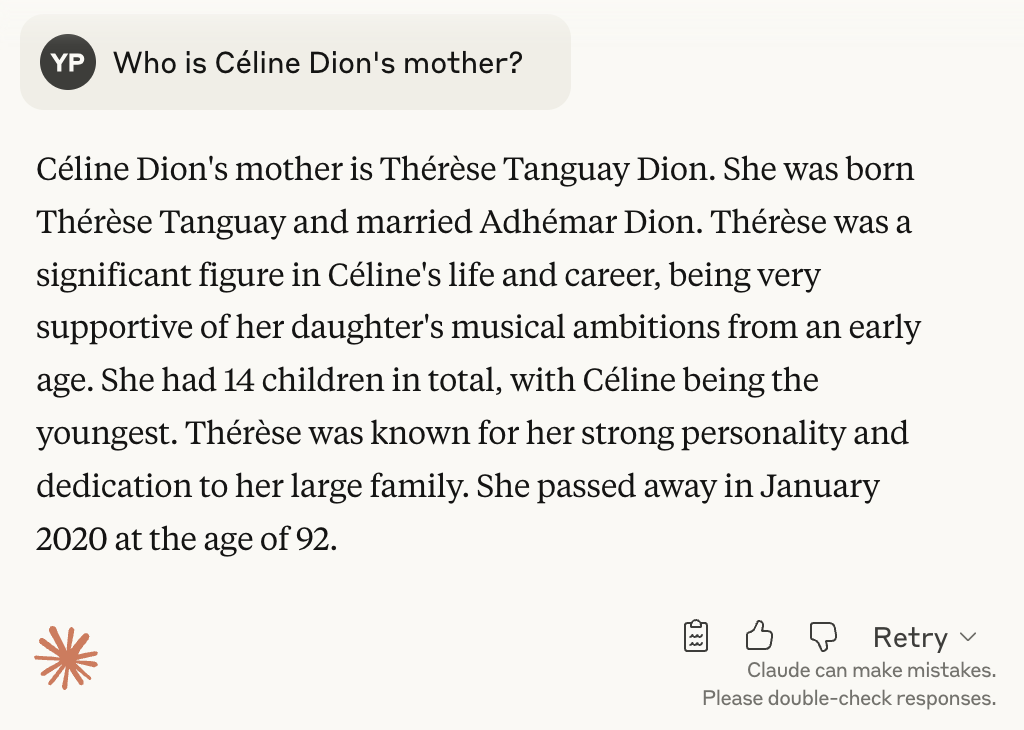
Claude Sonnet 4 knows Céline Dion’s mother…
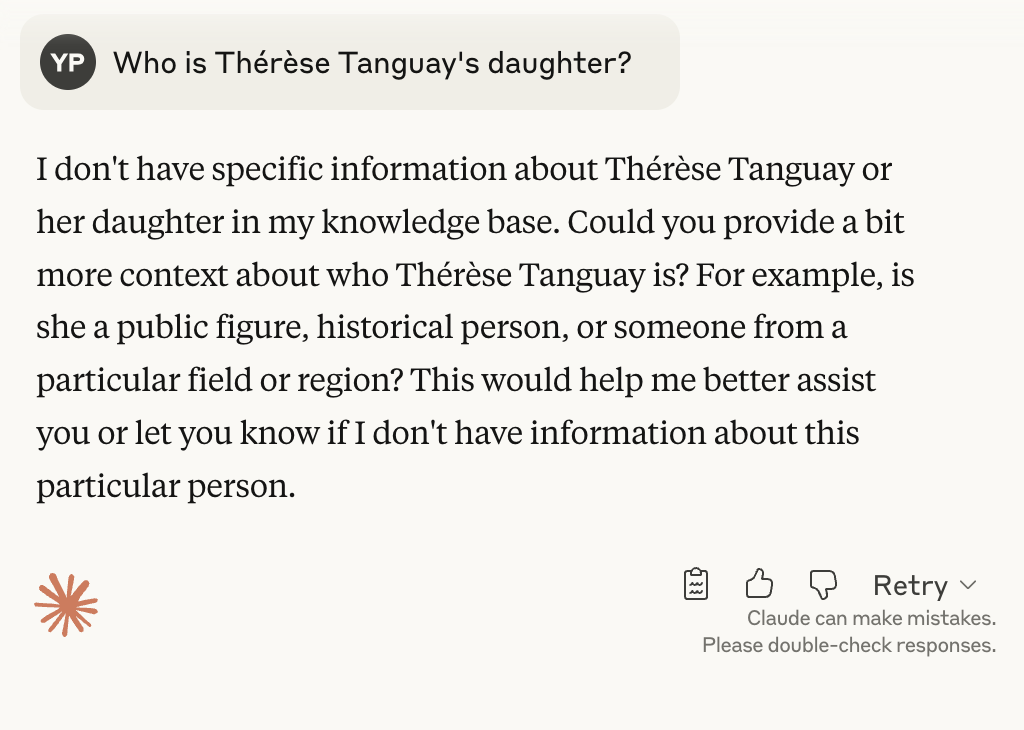
… but does not know her mother’s daughter.
Chain-of-verification (CoVe) prompts the model to fact-check its own response. This happens in four steps:
- The LLM gives an initial response,
- It plans verification questions to fact-check its initial response,
- It answers those questions one by one, and
- Generates a final, verified response on the basis of those answers.
Let’s take a look at the example from the original chain-of-verification paper to make this more clear. Assume we ask an LLM to name politicians who were born in New York. The initial response might mention Donald Trump (who was born in New York) alongside Hillary Clinton and Michael Bloomberg (who were born elsewhere). To weed out incorrect answers, the model plans verification questions next: for each politician on the list, it asks where they were born. As it answers these questions one by one, it becomes clear not all politicians meet the requirement. This information is used to compile a final list of correct answers.

Chain-of-verification prompts the model to fact-check its own initial response.
(Source: Dhuliawala et al. 2023)
You can split up this chain of verification into multiple prompts, or instruct the model to perform all steps in one prompt. A CoVe-inspired prompt for a list of promising writers younger than 40, for example, would instruct the model to compile an initial list first, then check each author’s date of birth, and conclude with a filtered list. When I presented Claude Sonnet 4 with this prompt, it correctly identified Tommy Orange and Hanya Yanagihara as mistakes in its initial list and came back with an error-free final list.
Unclear prompt
List 10 authors born in Belgium.
Clear prompt
- Give a list of promising writers younger than 40.
- For each of the writers, check their date of birth.
- Compile a final list of promising writers younger than 40.